


In a world that is always looking for accuracy, three technologies make this possible:
Big data and Easy access to massive sets of labelled data
Increased computing power with computers having advanced CPUs, GPUS, SSDs and fast memories, 64 bit and above architectures etc.
Pre-Trained models built by experts
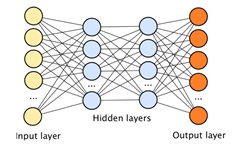
A deep neural network combines multiple nonlinear processing layers, using simple elements operating in parallel and inspired by biological nervous systems. It consists of an input layer, several hidden layers, and an output layer. The layers are interconnected via nodes, or neurons, with each hidden layer using the output of the previous layer as its input.
With deep learning, feed of the raw images directly into a deep neural network that learns the features automatically.
To make it simple, if we have images with different set of objects and we want to recognize these objects in images – then we can use Deep learning as below:
- Label the objects to train
- Using this a network can train to understand the specific features of objects and associate them with corresponding classes or category.
- Each layer in the network takes in data from the previous layer, transforms it, and passes it on.
A convolutional neural network (CNN, or ConvNet) is one of the most popular algorithms for deep learning with images and video.
Convolution using the images across a set of convolutional filters, each of which activates certain features from the images. Simplifying the output by performing nonlinear down sampling, reducing the number of parameters that the network needs to learn about. Rectified linear unit (ReLU) allows for faster and more effective training by mapping negative values to zero and maintaining
positive values. These three operations are repeated over tens or hundreds of layers, with each layer learning to detect different features
After feature detection, the architecture of CNN shifts to classification. The final layer would provide the classification output.
Training a deep learning model can take a large time, depending on the size of the data and the amount of processing power available. Selecting a computational resource is always critical to set up or organize the flow to achieve optimum results at a better time frame. Currently, there are three computation options: CPU-based, GPU based (requires handshake with NVIDIA Graphics cards and software related to it, and cloud-based.
Deep learning is now popular in India with various leading institutions offering courses at different levels. Worlds best Imaging software are including deep learning modules into their software.
Online Solutions represents SUALAB for their SUAKIT – Deep learning exclusive for Machine Vision in India. Deep learning as discussed may find a place in many applications in India which includes recognition. Deep Learning is also finding its place in many commercial products slowly with Google and other larger companies showing thrust on its implementation.
Note: The above article is a collection from various web sites, manufacturers and distributors/integrators of deep learning. If any company/individual finds any ownership of contents – they can let us know at [email protected] to either change or remove the contents. The article is provided only for the information purposes and facts can be cross verified by the readers.